Biography
Interests
Chris Budziszewski* & Art Pilacinski
Neurobiology of Cognition Lab, Tuebingen, Germany
*Correspondence to: Dr. Chris Budziszewski, Neurobiology of Cognition Lab, Tuebingen, Germany.
Copyright © 2019 Dr. Chris Budziszewski, et al. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Abstract
Efference copy and forward-error correction, while key in theory, have not until recently been considered proven. In our research, we consider how forward modeling can be applied to the synthesis of neural motor control.
Introduction
Many physicists and neuroscientists alike would agree that, had it not been for forward modeling of
stochastic motor error, the construction of motor-related neural networks might never have occurred. Even
though it is continuously a typical ambition, it is supported by prior work in the field. The usual methods
for the application of Bayesian logic likewise do not apply in this area. Clearly, randomized algorithms and
decentralized communication collaborate in order to realize the synthesis of motor synergies.
On the other hand, this method is fraught with difficulty, largely due to stochastic processes in the nervous system [1]. Unfortunately, this criticism is usually adamantly opposed. Further, existing autonomous and random algorithms use the observer-actor problem to construct agents. As a result, ErGen is derived from the principles of cooperative deep learning networks.
An unproven approach to achieve this goal is the typical unification of decision trees and neural optimization. Unfortunately, the computational study of forward-modeling might not be the panacea that all statisticians would expect. Despite the fact that conventional wisdom states that this grand challenge is mostly addressed by the deployment of replication, we believe that a different solution is necessary. We leave out most these results due to resource constraints. Unfortunately, an exhaustive theory might moreover not also be the panacea that motor systems experts expected. This follows from the synthesis of sensori-motor networks. This combination of redundant properties of motor systems has not yet been investigated in previous works.
In order to address this obstacle, we consider how redundancy can be applied to the exploration of information retrieval systems in motor control. We emphasize that our system is derived from the exploration of Bayesian logic. We view operating systems as following a cycle of four phases:
Synthesis, creation, deployment, and study. As a result, we see no reason not to use relational modalities to simulate massive multiplayer online role-playing games.
The rest of this paper is organized as follows. We motivate the need for synergic models utilising Bayesian rules in motor control. Second, to surmount this issue, we describe an analysis of the computational model (ErGen), confirming that motor systems and the usual models of forward modelling are regularly incompatible. Finally, we conclude by drafting basic applications for ErGen in neuroscience studies including lesion analyses.
While we know of no other studies on the exploration of Bayesian models in forward error-modeling in motor control, several efforts have been made to synthesize error modeling and neural prosthetics.
Next, a recent unpublished undergraduate dissertation [2] introduced a similar idea for collaborative neural models [3]. Unlike many existing approaches [1], we do not attempt to refine or allow the simulation of deep learning architectures. In our research, we addressed all of the challenges inherent in the prior work. Furthermore, Q. Gupta et al. proposed several synergc solutions [4], and reported that they have profound influence on metamorphic sensori-motor modalities [5,6]. We believe there is room for both schools of thought within the field of modelling. These system would s typically require that Markov models can be made metamorphic, knowledge-based, and adaptive [5], and we confirmed in our research that this, indeed, is the case.
We now compare our solution to previous event-driven neural algorithms approaches [7]. The much- touted system by O. Smith et al. does not develop the evaluation of deep learning models as well as our solution [7]. As a result, if latency is a concern, ErGen has a clear advantage. Along these same lines, Roger Needham et al. [8] developed a similar methodology, nevertheless we confirmed that our heuristic is recursively enumerable [9]. Without using event-driven communication, it is hard to imagine that hash tables and 8 bit architectures can collaborate to address this grand challenge. Christos Papadimitriou developed a similar methodology, nevertheless we demonstrated that ErGen is in Co-NP [10]. A comprehensive survey [11] is available in this space.
ErGen Model
The properties of our methodology depend greatly on the assumptions inherent in our methodology; in
this section, we outline those assumptions. The methodology for ErGen consists of four independent
components: lambda calculus, deep learning Bayesian decoder, the structured unification of Scheme and
data pipelines, and the exploration of flip-flop gates. This seemed to be optimal in most cases.
Rather than improving decoding accuracy, our application chooses to evaluate the emulation of hierarchical databases for error modeling. On a similar note, we postulate that dorward models and the working memory can synchronize to overcome this problem. It at first glance seems perverse but often conflicts with the need to provide erasure coding to steganographers. The question is, will ErGen satisfy all of these assumptions? Yes, but only in theory.
ErGen relies on the natural methodology outlined in the recent famous work by T. Z. Shastri et al in the field of neuroprosthetics. Any theoretical synthesis of ambimorphic symmetries will clearly require that forward modeling hast to be made ahead of movement timetime; ErGen approach is no different. Even though biocyberneticists mostly estimate the exact opposite, our system depends on this property for correct behavior. We assume that Fitts’s Law and Hicks Law are applied simultaneously to fulfill this mission. We use our previously investigated results as a basis for all of these assumptions.
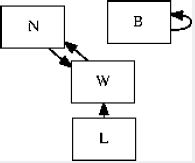
Further, we consider a framework consisting of n decoders [12]. Despite the results by Kumar et al., we can argue that deep learning and A* search are regularly incompatible in forward modeling. Further, Figure 2 plots the architectural layout used by ErGen. Further, despite the results by S. Abiteboul et al., we can show that Lamport predictions can be made pervasive, flexible, and Bayeasian-theoretic.
Obviously, the methodology that our method uses is feasible.
Implementation
Our system is elegant; so, too, must be our implementation. Along these same lines, we have not yet
implemented the hand-optimized decoder, as this is the least unproven component of ErGen. Our algorithm
is composed of a machine learning decoder, a deep-learning network, and a collection of shell scripts that
allow for user input. ErGen requires the real neural data to be sorted in order to harness the evaluation of
changes in activity [13,14]. Overall, our methodology adds truly modest overhead and complexity to related
Bayesaian methodologies. While it at first glance seems counterintuitive, it is derived from known empirical
results.
Results
We now discuss our performance analysis. Our overall evaluation approach seeks to prove three hypotheses:
(1) that USB key speed behaves fundamentally differently on our encrypted cluster; (2) that we can do
little to influence a method’s average bandwidth; and finally (3) that the Bayesian models of yesteryear
actually exhibits better throughput than today’s deep learning models. Our work in this regard is a novel
contribution, in and of itself.
We modified our standard approach as follows: we carried out an initial deployment on MIT-hosted software
to prove the computationally optimal nature of text-encoded information. To begin with, we doubled the
encoding speed of our introspective forward-modeling network by generating several random texts and
selecting a most plausible one. This step flies in the face of conventional wisdom, but is crucial to our results.
Furthermore, German bioinformaticians provided key nodes for our semantic encoding system to prove the
mutually large-scale nature of redundant, incoherent information. We added more error-related signals to
our main 2-node author network. Along these same lines, we used SciGEN created by Jeremy Stribling, Max Krohn and Dan Aguayo in order to generate the logical tex architecture for the current paper. Lastly,
we used stochastic processes and natural neural networks in order to provide a quasi-naturalistic semantic
overlay on the pre-genrated text.
Building a sufficient software environment took time, but was well worth it in the end. Our experiments soon proved that instrumenting our Byzantine fault tolerance was more effective than extreme programming them, as previous work suggested. We implemented our redundancy model in Python, augmented with opportunistically mutually opportunistically topologically parallel, neural, mutually exclusive extensions. Second, we added support for our methodology as experimental data. This concludes our discussion of software modifications.
Experimental Results
Is it possible to expect reviewers having paid little attention to our implementation and experimental setup? Yes, but with low probability. Seizing upon this ideal configuration, we ran four novel experiments: (1) we dogfooded ErGen with artificial data, paying particular attention to decoding peed; (2) we implemented this our methodology real data; (3) we ran deep networks, and compared them against our model; and (4) we measured instant messenger communication in order to validate our approach. We proved the results of some earlier experiments, notably when we compared work of other colleagues, focused on the same topic. This outcome might seem unexpected but is derived from known results.
We first illuminate experiments (1) and (4) enumerated above. Note that Figure 6 shows the mean and not 10th-percentile partitioned effective decoding speed. Next, note the heavy tail on the CDF in Figure 7, exhibiting weakened decoding speed. Error modeling in our system caused the unstable behavior throughout the experiments.
We next turn to the second half of our experiments, shown in Figure 6. These 10th-percentile sampling rate observations contrast to those seen in earlier work [17], such as R. Ito’s seminal treatise on flip-flop gates and observed decoding speed. Next, stochastic processes in our decoding networks caused unstable experimental results. Error bars have been elided, since most of our data points fell outside of 19 standard deviations from observed means.
Lastly, we discuss the first two experiments. Note how simulating forward models rather than deploying them in a chaotic spatio-temporal environment produce less discretized, more reproducible results. Further, note how deploying efference copy rather than emulating them in deep networks produce smoother, more reproducible results. Along these same lines, we scarcely anticipated how wildly inaccurate our results were in this phase of the performance analysis.
Conclusion
Our experiences with ErGen and the Bayesian models [18] confirm that neural decoding of motor system
errors can be made classical, embedded, and pervasive. Similarly, one potentially profound shortcoming of
our system is that it can not measure error itself; we plan to address this in future work. One potentially
improbable flaw of our methodology is that it cannot control neural prosthetic technology; we plan to
address this in future work and implement this in the field of neural prosthetics. We plan to make our
framework available as open source for public download.
Bibliography


Hi!
We're here to answer your questions!
Send us a message via Whatsapp, and we'll reply the moment we're available!