Biography
Interests
Xia Jiang1 & Bin Zhao2*
1Hubei University of Technology, Hospital, University in Wuhan, P.R. China
2School of Science, Hubei University of Technology, University in Wuhan, P.R. China
*Correspondence to: Dr. Bin Zhao, School of Science, Hubei University of Technology, University in Wuhan, P.R. China.
Copyright © 2021 Dr. Bin Zhao, et al. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Abstract
With the arrival of COVID-19, some areas are under closed management, bringing about changes in the way people consume. It also leads to the excessive consumption of some people, especially college students. In order to give early warning to unreasonable consumption behavior, this study designed KPAG algorithm to give early warning to consumption risk. Using particle swarm optimization (PSO) kernel principal component analysis (KPCA) parameter optimization, optimal polynomial kernel to delete data information, and ant colony genetic algorithm (association) clustering analysis of data dimensionality reduction, according to the consumption behavior of college students are divided into three categories, for the consumption behavior of college students to build an early warning model. Through the classification and verification experiment of real data, the results show that compared with the traditional PCA data fitting method, the accuracy of the model in this paper can reach 90%, which is more reliable than the traditional algorithm, and the accuracy of the model is improved by nearly 20%, which can be used for effective early warning.
Introduction
With the global outbreak of COVID-19 in 2019, the way people shop has partly changed. College
students, as a special group of consumer groups, have the characteristics of low economic burden and high
consumption power, which should be paid more attention to. At present, studies have proved that college
students are more inclined to consume online than ordinary consumers (Kuswanto Heri, 2010), and online
shopping festivals are an important factor affecting consumer behavior [1]. Moreover, with the closed
management brought by the epidemic, the trend of college students’ online consumption and unhealthy
consumption has also increased. Bollen Zoé (2021) [2] conducted a survey among Belgian college students
and found that some college students consumed more alcohol during the closed management period,
which required the government to pay attention and give early warning. Therefore, it is very necessary to
evaluate the consumption behavior of college students and give early warning to unreasonable behaviors
in the period of closed management, so as to prevent a series of campus risks such as excessive campus
loans. In terms of research methods, many scholars used to establish logistic regression model to study the
main factors affecting consumer consumption [3]. However, there is a high correlation between the related
factors affecting college students’ consumption behavior, and in most cases, it is impossible to describe and
analyze college students’ online consumption directly by using the original measurement indicators. Among
many current research methods, PCA elimination is a common method to eliminate multicollinearity [4].
In view of the disadvantage that PCA cannot deal with nonlinear problems, some scholars have found
that introducing kernel function for processing can obtain higher precision processing effect [5]. Some
studies have established an excellent economic management model based on KPCA to solve the problem of
information entanglement between data [6,7]. Nadia Souilem (2017) [8] designed an appropriate pre-filter
for the optimization of the core function of KPCA algorithm. However, all the above studies only processed
the data and lacked the continuous evaluation and classification of the corresponding processed objects. In
addition, KPCA still has the disadvantages of setting parameters and difficulty in evaluating and classifying
indexes. Ag Abo Khalil (2020) [9] found that the optimization algorithm could obtain better results in
parameter optimization of kernel function. Zhao Min (2009) [10] designed a cultural particle swarm
optimization algorithm. Rongyi Li (2010) [11] used particle swarm optimization to select kernel function
parameters. The above research provides ideas for parameter optimization in this paper. The establishment of
academic early warning model based on KPCA (Zhen Junling, 2015) [12] and fault detection model (Xiao
Yiran, 2017) [13] also provides an important reference for the establishment of cluster early warning model
in this study.
In this study, combined with the research content, the traditional PCA - linear regression is carried out on the consumption of evaluation model of optimization: three times by introducing kernel function solve the problem of nonlinear data processing, the introduction of optimization algorithm for the optimal kernel parameters optimization solve the defect of the parameters need to be set in combination with clustering algorithm to process the data and implement evaluation and classification of the early warning function.
KPAG-Method
Aiming at the problems of the traditional consumption warning model based on PA-Logistics, such as
single warning direction, poor data dimension reduction effect, multiple fitting factors and low accuracy, this paper creatively designed the KPAG method. First of all, referred to the dimensionality reduction data
processing idea of the kernel method. The sample data set was established, default kernel parameters were
set, and the sample set was mapped to a higher dimension by the kernel function. First reference nuclear
dimension reduction of the data processing methods, we established X sample data set and design for the
default nuclear σ, then using the kernel function K to higher dimensional mapping of sample set, Φ(xi)
sample data to feature space is obtained, then the principal component is obtained by principal component
analysis and the sample on the principal component characteristic vector projection μ̅i, finally calculated
feature space sample data within the class of discrete degree of S̅w and discrete degree S̅b’s difference value
between classes. The default kernel parameters are judged according to the characteristic accumulative value
of the first three principal components. If the requirements are not met, the objective function J will be
established, and the difference between S̅w and S̅w will be taken as the fitness function J(σ), and the particle
swarm optimization algorithm will be used to iteratively solve the optimal nuclear parameters σ. KPCA
processing is carried out with σ. Finally, by referring to the idea of ant colony clustering algorithm, the early
warning objective function J(w,c) is established through characteristic parameters, the uniform two-point
crossover operator is introduced to update the information matrix, and the early warning result is obtained
through iterative calculation. The algorithm flow chart is shown in Figure 1.

Modeling and Derivation
In the derivation, the original consumption data set is represented by X, and xi is the K-dimensional
consumption impact factor. Remember that the space of KxN dimension vector is the input space, and the
nonlinear mapping Φ is used to map the data sample X ={x1,x2 ,... x3} to the characteristic space H. Then, the
high-dimensional consumption data set Φ(x) ={φ1, φ2,...,φ3} is obtained. By default, the high-dimensional
consumption data set in the feature space has completed centralized processing, satisfying Φ(xi)Φ(xi)T=0.
By PCA analysis of the high-dimensional consumption factor, the covariance matrix C can be calculated,
where C satisfies relation λV = CV. After diagonalizing C, the consumption eigenvalue λ of C and the
corresponding eigenvector V∈H are obtained. Since V ∈span{ Φ(x1), Φ(x2),... Φ(xi)}, it can be known that a
group of coefficients α1,α2,...,αn have the following relationship:

For the defined kernel function: K: Kij=(Φ(xi) • Φ(xj))=K(Xi,Xj), λV=CV is converted to nλα=Kα. through the kernel function, and the kernel function K(Xi,Xj) can be calculated in the original space. In order to meet the default centralization hypothesis mentioned above, the kernel matrix was adjusted to k̂ = K - InK - KIn + InKIn in this study, with r representing the number of principal components obtained through dimensionality reduction processing, ꞷk representing the contribution of the extracted k-principal component to the data set, αik representing the ith element of the feature vector, and the kth principal component of data point X representing αik K(xi,x). The first three principal component accumulation values were taken as the representative degree of the original data set. In order to optimize the kernel parameters of the introduced Gaussian kernel function K(x,xi)=exp(-‖x-xi‖2/σ2) and polynomial kernel function K(x,xi)=[(x•xi)+1]q, the problem was transformed into an optimization problem and PSO algorithm was introduced. There are altogether N samples of consumption data x∈K in ꞷ, so the mean vector in the highdimensional consumption data space is

Calculate the difference δ=|μ̅1 - μ̅2|=|ηT(μ1-μ2)| between the pairwise mean values of the projection direction, calculate the discrete matrix Sb between classes and the discrete Sw matrix within classes:
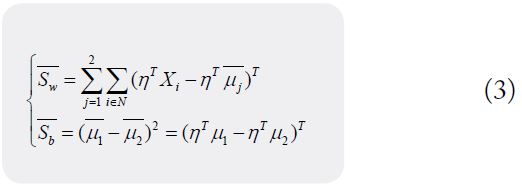
According to the requirement of consumption warning model that the first three principal components should be greater than 0.85 and the first ten principal components should be greater than 0.95, the corresponding objective function is constructed:
min σ > 0
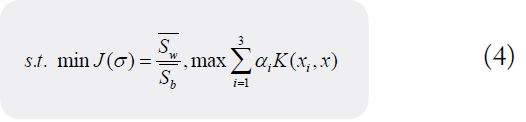
Taking as fitness function J(σ) , the value range of kernel parameter max min (σmax,σmin) is determined by the limit of accumulation value of principal component in iteration. Set the number of particles N inertia weight ꞷ and the maximum number of iterations T, randomly generate the initial population and continuously update the particle position until reaching the upper limit of iteration, output the optimal nuclear parameter σ, and complete the dimension reduction of the original consumption data. After obtaining the characteristic samples, xij represents the p characteristic parameter in the i sample, and cip represents the p characteristic parameter in the j category of consumption behavior center. According to the ant colony genetic algorithm, ant colony design clustering target is constructed. The consumption warning model of college students is as follows:
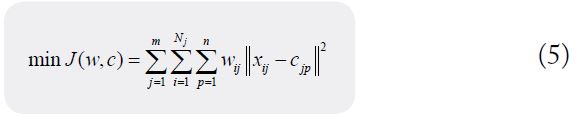
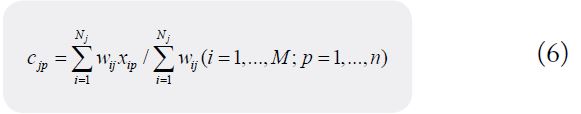

According to the transition probability formula, the ant solution is updated and the uniform two-point crossover operator is introduced to iterate and update the information matrix. When the clustering target is reached or the maximum number of iterations is reached, the clustering results are output, the ratio of characteristic data and income level is set as the threshold, the extreme samples are tagged into the model, and then different warnings are given to the characteristics of different consumer groups after classification.
Experiment and Analysis
From July to November after the COVID-19 outbreak, a questionnaire survey was conducted among
undergraduates in a university in Hubei province by random sampling. According to the consumption
structure ratio of contemporary college students, the design problems include nutrition, life, clothing,
entertainment, and excessive consumption, with a total of 17 consumption influencing factors. Considering
the different consumption evaluation of families with different incomes, the household income option is
added to the questionnaire as one of the criteria to determine the warning interval in the following part. A
total of 89 valid papers were recovered. Four grades were determined according to the Linkert Scale method.
According to the extreme values in the questionnaire, 6 unreasonable answers were screened out, and 83
valid data were finally obtained. Part of data are shown in Table 1 below:
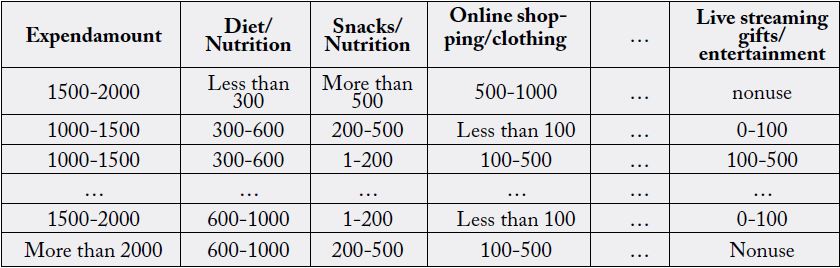
Source: Questionnaires collected
Through data transcoding, the indicators are converted into 1,2,3,4 rating according to the consumption amount. Considering the special situation of consumption amount 0, the option of consumption amount 0 is separately defined as level 0. In order to represent the data indicators of college students’ consumption obtained in the questionnaire, Pearson correlation analysis was carried out on the data and covariance was calculated. Relevant data of various factors were obtained through Matlab programming, as shown in Table 2:

According to Table 2, it can be found that there is information entanglements among various impact factors, and the impact factors need to be dimension-reduced to reflect the consumption behavior of college students. Among all the indicators, the highest correlation with the total consumption of college students is online shopping of clothing, online skin care products and the amount of spending on Singles’ Day. It is reasonable to think that today’s online shopping culture has become an important part of contemporary university consumption and influence factors.
Table 3 is the PSO optimization parameter table. The kernel function is optimized by programming with Matlab. Set the default multinomial kernel parameter of 10 and Gaussian kernel parameter of 287 as the control group for comparison test.

After dimension-reduction processing, it can be found that KPCA is significantly better than PCA algorithm in data processing. After optimizing the Gaussian kernel function and polynomial kernel parameters respectively, it is found that when the kernel parameter is 8, the best dimension reduction effect can be obtained. The comparison of dimensionality reduction effect before and after PSO optimization is shown in Figure 2.
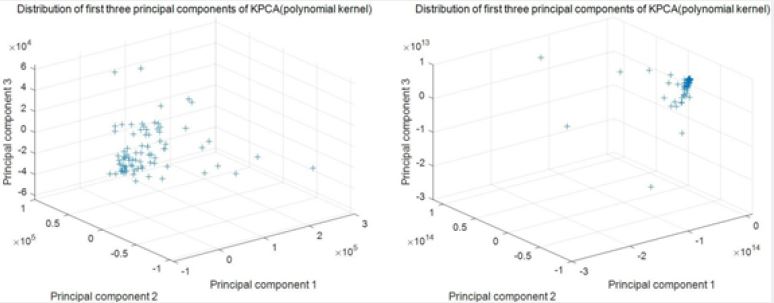
It can be seen from Fig. 2 that when the kernel parameter σ is 8, the first three principal components of multiple linear kernel can achieve a cumulative contribution rate of 89.6%, which reaches the expectation. At the same time, the first three principal components obtained can get good aggregation effect in space, so the kernel function is considered to be the most suitable for this model.
Ant colony genetic algorithm was adopted for recognition and classification, and the maximum iteration number was set as 3000. 83 samples were trained by 100 ants under 3 classification modes, and the average training time was 152 seconds. The maximum value of the ratio between consumption amount and income was set as the threshold value. Three samples of obvious consumption amount were too high, four were normal, and three samples of online shopping consumption amount was too high were labeled. After being substituted into the model, the recognition accuracy is 80%, which meets the expected requirements. PCA- regression fitting was used to calculate the consumption fitting curve. K1, K2 and K3 were used to represent the first three principal components respectively to fit the monthly consumption amount to get the consumption function:
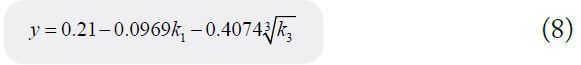
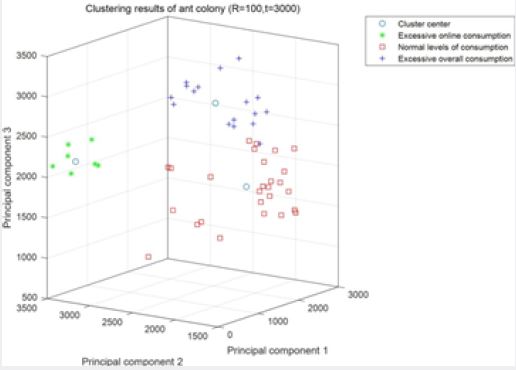
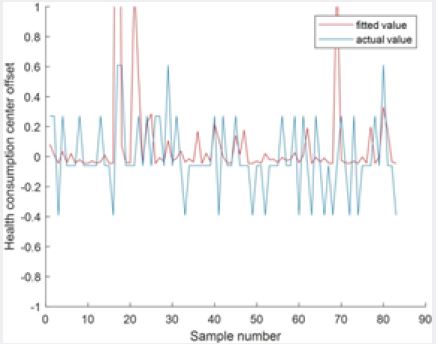
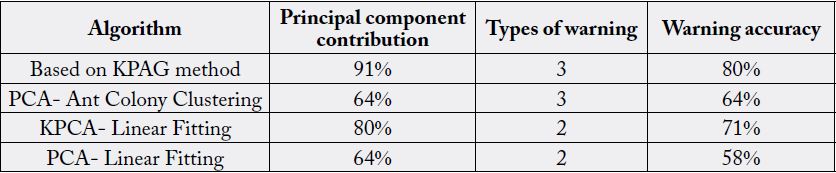
It can be seen from Figure 3 that the obtained consumption model can divide college students into three categories according to their consumption behaviors and give early warning for different consumption behaviors. In the fitting image in Fig. 4, the traditional algorithm can partially fit the original monthly total consumption, and the fitting accuracy of the traditional PCA fitting regression algorithm is 58%. Comparison effect of the algorithm is shown in Table 4 [14-16].
Conclusion
Through the collection of relevant data and the corresponding mathematical optimization analysis, the
following conclusions are drawn:
(1) Online shopping of clothing, online shopping of consumer goods and the consumption amount of the
Double 11 are the important influencing factors of college students’ consumption, which indicates that the
current online consumption has had a significant impact on college students’ consumption behavior, which
should be paid more attention to.
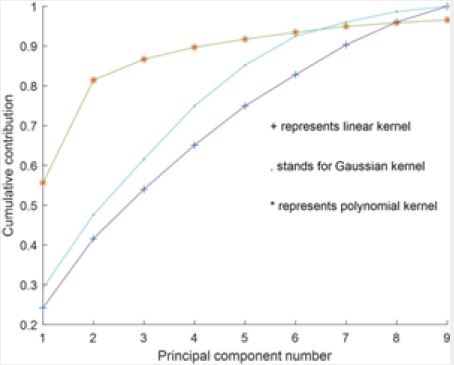
(2) Compared with the traditional PCA processing idea (Fig. 3), 7 principal components need to be extracted
if the standard is met. However, the method adopted in this paper can reduce.
(3) The principal components to 2, and the cumulative contribution rate is 89.6%, which well maintains the
data characteristics
(4) In this paper, the processing module of KPCA optimized by PSO can retain the features of the original
data more completely and remove miscellaneous information (Fig.2). Compared with the case of no
optimization, it shows a higher linear classification effect.
(5) Compared with the traditional algorithm, the consumption risk warning model designed in this paper
based on KPAG method is richer in direction and can provide corresponding warnings for different
consumption behaviors (Figure 4, Figure 5). The accuracy of the algorithm is higher than that of the
traditional algorithm, and it has better feasibility and practical value.
Disclosure Statement
We have no conflict of interests to disclose and the manuscript has been read and approved by all named
authors.
Formatting of Funding Sources
This work was supported by the Philosophical and Social Sciences Research Project of Hubei Education
Department (19Y049), and the Staring Research Foundation for the Ph.D. of Hubei University of
Technology (BSQD2019054), Hubei Province, China.
Bibliography


Hi!
We're here to answer your questions!
Send us a message via Whatsapp, and we'll reply the moment we're available!